Fine Tune Llms To Learn Neo4j's Cypher
Discover how to fine-tune Large Language Models (LLMs) to proficiently grasp Neo4j's Cypher query language, enabling seamless navigation and comprehension of graph database querying
NB: The full code for this tutorial is set up in my Github Repo, with setup instruction for Docker as well
Loading dependencies:
Graph databases, such as Neo4j, offer a powerful way to model and query interconnected data. Cypher, Neo4j's query language, plays a crucial role in navigating and extracting insights from these graphs. However, mastering Cypher requires time and effort. In this blog post, we'll explore how to leverage Large Language Models (LLMs) to fine-tune their understanding of Cypher, enabling seamless navigation and comprehension of graph database querying.
Introduction to Large Language Models (LLMs)
Large Language Models, such as OpenAI's GPT series, have revolutionized natural language processing tasks. These models, trained on vast amounts of text data, excel in understanding and generating human-like text. Recently, researchers and practitioners have begun exploring the capabilities of LLMs in domain-specific tasks, including programming languages and specialized query languages like Cypher.
Understanding Cypher
Cypher is a declarative query language specifically designed for graph databases. Its syntax resembles ASCII art, making it highly expressive and intuitive for querying graph structures. However, mastering Cypher requires understanding its unique syntax, patterns, and querying techniques.

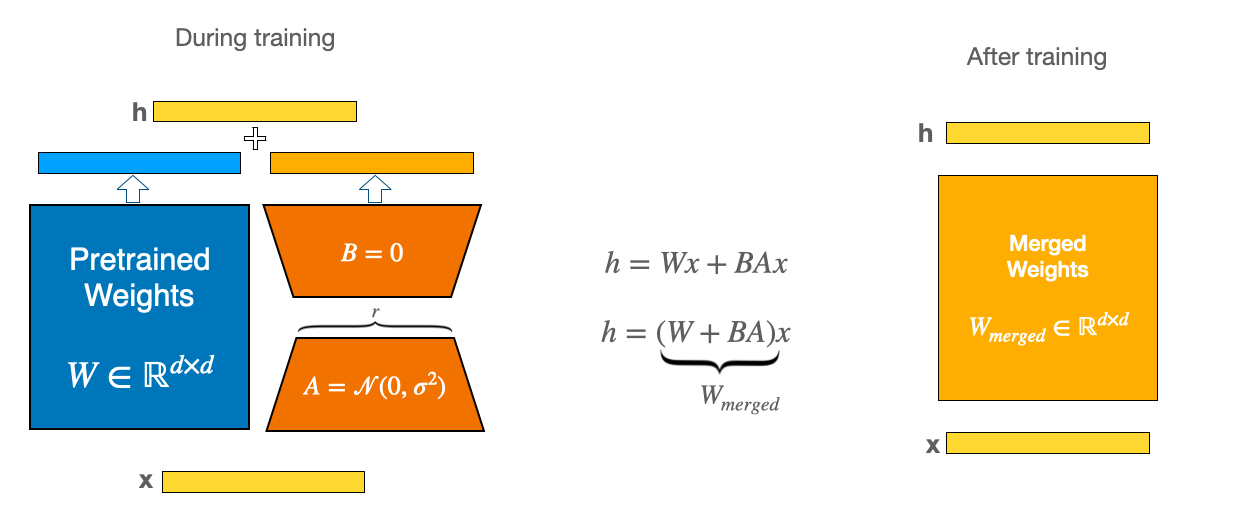
Fine-Tuning with Peft and LoRA
LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning method that introduces trainable rank decompositions to the weight matrices of a pre-trained model. This approach allows for efficient adaptation to specific tasks while minimizing the number of trainable parameters, thereby reducing computational requirements and memory footprint.
PEFT (Parameter-Efficient Fine-Tuning), on the other hand, is a broader framework that encompasses various parameter-efficient fine-tuning techniques, including LoRA. PEFT aims to fine-tune large pre-trained models with significantly fewer trainable parameters, making the process more efficient and scalable.
Step 1: Data Preparation
For this example, we'll use a dataset consisting of 500 examples of natural language descriptions and their corresponding Cypher queries. This dataset was generated using GPT-4 and can be found in my Github Repository. The dataset is in CSV format, with each row containing a natural language description and its corresponding Cypher query.
Step 2: Model Selection and Setup
For this example, we'll use the CodeLLaMA model, a powerful language model trained specifically for code and natural language understanding. CodeLLaMA has shown excellent performance in various code-related tasks, making it a suitable choice for our Cypher query fine-tuning task.
# Model names
model_name = "daryl149/llama-2-7b-chat-hf"
# Activate 4-bit precision base model loading (bool)
load_in_4bit = True
# Activate nested quantization for 4-bit base models (double quantization) (bool)
bnb_4bit_use_double_quant = True
# Quantization type (fp4 or nf4) (string)
bnb_4bit_quant_type = "nf4"
# Compute data type for 4-bit base models
bnb_4bit_compute_dtype = torch.bfloat16
# Load the model
bnb_config = BitsAndBytesConfig(
load_in_4bit = load_in_4bit,
bnb_4bit_use_double_quant = bnb_4bit_use_double_quant,
bnb_4bit_quant_type = bnb_4bit_quant_type,
bnb_4bit_compute_dtype = bnb_4bit_compute_dtype,
)
model, tokenizer = load_model_tokenizer(model_name, bnb_config)For this example, we'll use the CodeLLaMA model, a powerful language model trained specifically for code and natural language understanding. CodeLLaMA has shown excellent performance in various code-related tasks, making it a suitable choice for our Cypher query fine-tuning task.
Step 3: Define LoRA Configuration
def create_peft_config(r: int, lora_alpha: int, target_modules, lora_dropout: float, bias: str, task_type: str) -> LoraConfig:
"""
Create the Parameter Efficient Fine-Tuning configuration.
Returns:
LoraConfig: _description_
"""
config = LoraConfig(
r = r,
lora_alpha = lora_alpha,
target_modules = target_modules,
lora_dropout = lora_dropout,
bias = bias,
task_type = task_type,
)
return config
################################################################################
# QLoRA parameters
################################################################################
# Number of examples to train (int)
number_of_training_examples = 1000
# Number of examples to use to validate (int)
number_of_valid_examples = 200
# Dataset Name (string)
dataset_name = "b-mc2/sql-create-context"
# LoRA attention dimension (int)
lora_r = 16
# Alpha parameter for LoRA scaling (int)
lora_alpha = 64
# Dropout probability for LoRA layers (float)
lora_dropout = 0.1
# Bias (string)
bias = "none"
# Task type (string)
task_type = "CAUSAL_LM"
STEP 4: Setup the model for training
def preprare_model_for_fine_tune(model: AutoModelForCausalLM,
lora_r: int,
lora_alpha: int,
lora_dropout: float,
bias: str,
task_type: str) -> AutoModelForCausalLM:
# Enable gradient checkpointing to reduce memory usage during fine-tuning
model.gradient_checkpointing_enable()
# Prepare the model for training
model = prepare_model_for_kbit_training(model)
# Get LoRA module names
target_modules = find_all_linear_names(model)
# Create PEFT configuration for these modules and wrap the model to PEFT
peft_config = create_peft_config(lora_r, lora_alpha, target_modules, lora_dropout, bias, task_type)
model = get_peft_model(model, peft_config)
model.config.use_cache = False
return model
model = preprare_model_for_fine_tune(model, lora_r, lora_alpha, lora_dropout, bias, task_type)STEP 5: Finetune the model
def fine_tune(model: AutoModelForCausalLM, trainer: Trainer, output_dir: str) -> None:
"""
Fine-tune the model.
Args:
model (AutoModelForCausalLM): The model to fine-tune.
trainer (Trainer): The trainer with the training configuration.
output_dir (str): The output directory to save the model.
"""
print("Training...")
train_result = trainer.train()
save_metrics(train_result, trainer)
save_model(trainer.model, output_dir)
# Training parameters
trainer = Trainer(
model = model,
train_dataset = preprocessed_dataset,
args = TrainingArguments(
per_device_train_batch_size = per_device_train_batch_size,
gradient_accumulation_steps = gradient_accumulation_steps,
warmup_steps = warmup_steps,
learning_rate = learning_rate,
fp16 = fp16,
logging_steps = logging_steps,
output_dir = output_dir,
optim = optim,
num_train_epochs=num_train_epochs
),
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm = False))
### Start training
fine_tune(model, trainer, output_dir)
Step 6: Fine-Tuning Iterations and Refinement
Depending on the performance of the fine-tuned model, you may need to iterate and refine the fine-tuning process. This could involve adjusting the LoRA configuration, trying different pre-trained LLMs, or augmenting the training dataset with additional examples.
Conculsion
Fine-tuning Large Language Models (LLMs) using techniques like LoRA and PEFT opens up new possibilities for enhancing our querying capabilities with graph databases like Neo4j. By training LLMs on Cypher query datasets, we can unlock a range of powerful features, including improved query comprehension, query generation, explanation, and optimization. As the field of natural language processing continues to evolve, we can expect even more advanced techniques and applications for fine-tuning LLMs to specific domains and tasks.