Vector Databases: What Lies Behind the Hype?
This guide explores vector databases, an emerging technology for efficiently storing and searching high-dimensional data, while diving into their intricacies and uncovering their pros and cons.
In the era of large language models (LLMs) and AI-powered applications, the ability to efficiently store, search, and analyze unstructured data has become increasingly important. One of the key enabling technologies for this is the use of embeddings – dense vector representations of text, images, or other data types that capture their semantic meaning and relationships.
LLMS and embeddings
Large language models like GPT-3, BERT, and others have revolutionized the way we work with text data. By training on vast amounts of textual data, these models can generate highly contextual and semantically rich embeddings – numerical vector representations that capture the underlying meaning and relationships within the text.
These embeddings can be thought of as points in a high-dimensional vector space, where similar texts or concepts are clustered together, enabling powerful capabilities like semantic search, text summarization, and recommendation systems.
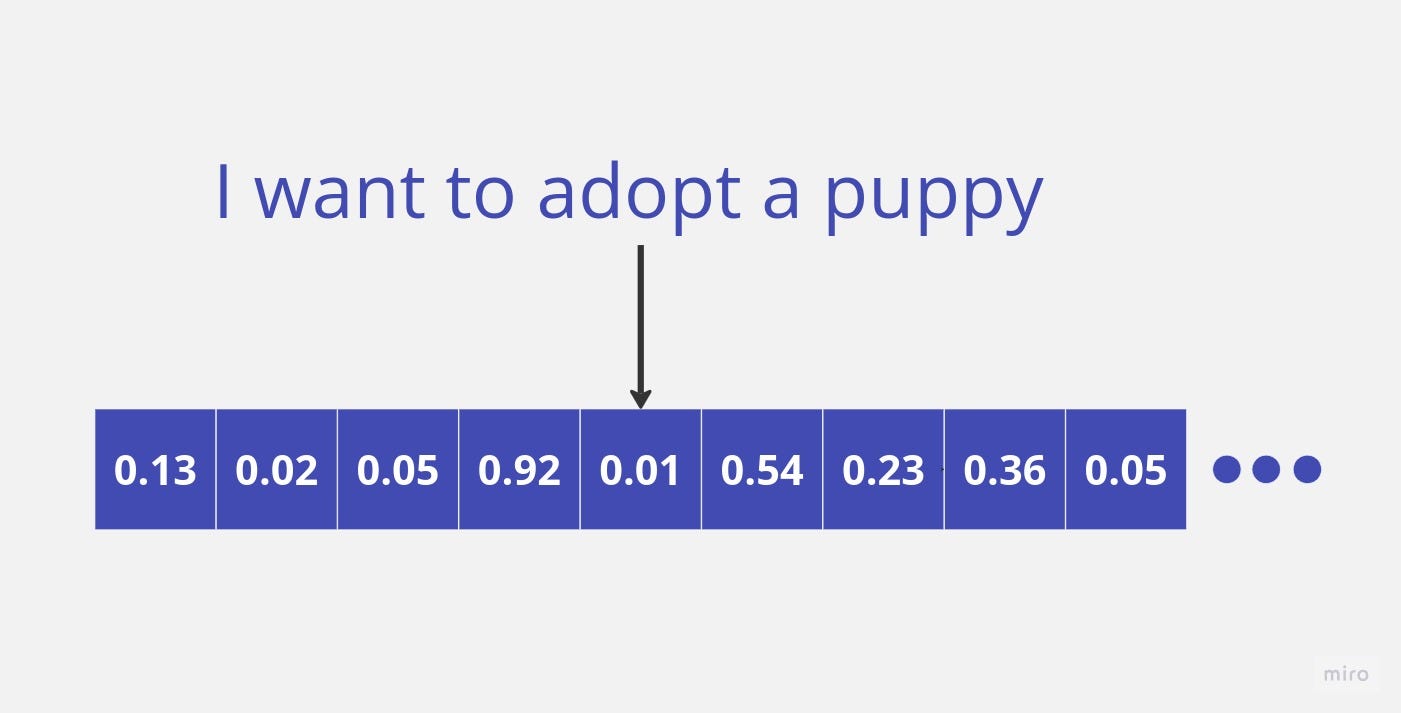
However, working with these high-dimensional embeddings at scale poses significant challenges. Traditional databases and search engines are ill-equipped to handle the complexities of vector data, making it difficult to store, index, and efficiently retrieve relevant information based on semantic similarity.
Vector Databases
Vector databases are specialized data stores designed to efficiently store, index, and search high-dimensional vector data, such as embeddings generated by LLMs. By leveraging advanced indexing techniques and similarity search algorithms, vector databases enable fast and accurate retrieval of relevant information based on semantic similarity, rather than relying solely on exact keyword matches.
This capability has numerous applications across industries, from e-commerce recommendation systems and personalized content discovery to anomaly detection in cybersecurity and fraud prevention.
Now, we'll take a deep dive into some of the most popular vector database solutions, exploring their unique features, strengths, and weaknesses. We'll also provide hands-on code examples, demonstrating how to perform common operations like creating vectors, indexing, and similarity search.
FAISS
FAISS (Facebook AI Similarity Search) is a powerful open-source library for efficient similarity search and clustering of high-dimensional vectors, developed by Meta AI Research. Its lightweight nature, extensive support for various distance metrics and indexing techniques, and seamless integration with popular machine learning frameworks like PyTorch and TensorFlow make it a versatile choice for a wide range of applications.
import numpy as np
import faiss
# Create vectors
vectors = np.random.rand(1000, 128).astype('float32')
# Create index
index = faiss.IndexFlatL2(128)
index.add(vectors)
# Similarity search
query = np.random.rand(1, 128).astype('float32')
distances, indices = index.search(query, 10) Weaviate
Weaviate is an open-source vector database that combines the power of vector search with the flexibility of a knowledge graph. Built on top of the popular open-source Datastax Cassandra database, Weaviate offers a rich set of features for building intelligent, data-driven applications.
import weaviate
# Connect to Weaviate instance
client = weaviate.Client("http://localhost:8080")
# Create a schema
client.schema.create_class("Publication", batching_config={"max_ops": 1000})
# Add data objects
import numpy as np
vectors = np.random.rand(1000, 128).astype('float32')
client.data_object.create(
class_name="Publication",
objects=[
{"vector": vector.tolist()} for vector in vectors
]
)
# Similarity search
query = np.random.rand(1, 128).astype('float32')
results = (
client.query.get("Publication", ["vector"])
.with_near_vector({"vector": query.tolist()})
.with_limit(10)
.do()
)
Milvus
Milvus is an open-source vector database designed for scalability and performance. Built with a highly modular architecture, Milvus offers a range of customization options, allowing you to tailor it to your specific needs while still benefiting from its robust vector search capabilities.
from milvus import Milvus, MetricType, IndexType
# Connect to Milvus
client = Milvus()
# Create a collection
client.create_collection(
"my_collection",
fields=[
{"name": "vector", "type": MetricType.FLOAT_VECTOR, "dim": 128}
],
index_file_size=1024
)
# Insert vectors
import numpy as np
vectors = np.random.rand(1000, 128).astype('float32')
client.insert(
collection_name="my_collection",
records=[{"vector": vector.tolist()} for vector in vectors]
)
# Build index
client.create_index(
"my_collection",
IndexType.IVF_FLAT,
{"nlist": 1024}
)
# Similarity search
query = np.random.rand(1, 128).astype('float32')
results = client.search(
collection_name="my_collection",
query_records=[{"vector": query.tolist()}],
top_k=10
)
Pinecone
Pinecone is a fully managed vector database service that aims to simplify the process of building and deploying vector search applications. By abstracting away much of the underlying infrastructure and operational complexity, Pinecone allows developers to focus on building their applications without worrying about scaling, sharding, or managing clusters.
import pinecone
# Initialize Pinecone
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")
# Create an index
index = pinecone.Index("my-index")
# Upsert vectors
import numpy as np
vectors = np.random.rand(1000, 128).astype('float32')
ids = [f"vector_{i}" for i in range(len(vectors))]
index.upsert(vectors=vectors.tolist(), ids=ids)
# Similarity search
query = np.random.rand(1, 128).astype('float32')
results = index.query(
query_vectors=[query.tolist()],
top_k=10,
include_metadata=True
)
Other Vector Databases:
While the databases covered above are among the most popular, there are several other vector database solutions available, including Qdrant (user-friendly with sharding support), Chroma (designed for LLM embeddings), Vespa.ai (open-source with advanced linguistics capabilities), and more. Each solution has its own strengths, weaknesses, and unique features catering to different use cases and requirements.